Publications
Actor-Transformers for Group Activity Recognition
This paper strives to recognize individual actions and group activities from videos. While existing solutions for this challenging problem explicitly model spatial and temporal relationships based on location of individual actors, we propose an actor-transformer model able to learn and selectively extract information relevant for group activity recognition. We feed the transformer with rich actor-specific static and dynamic representations expressed by features from a 2D pose network and 3D CNN, respectively. We empirically study different ways to combine these representations and show their complementary benefits. Experiments show what is important to transform and how it should be transformed. What is more, actor-transformers achieve state-of-the-art results on two publicly available benchmarks for group activity recognition, outperforming the previous best published results by a considerable margin.
arXiv,
2020
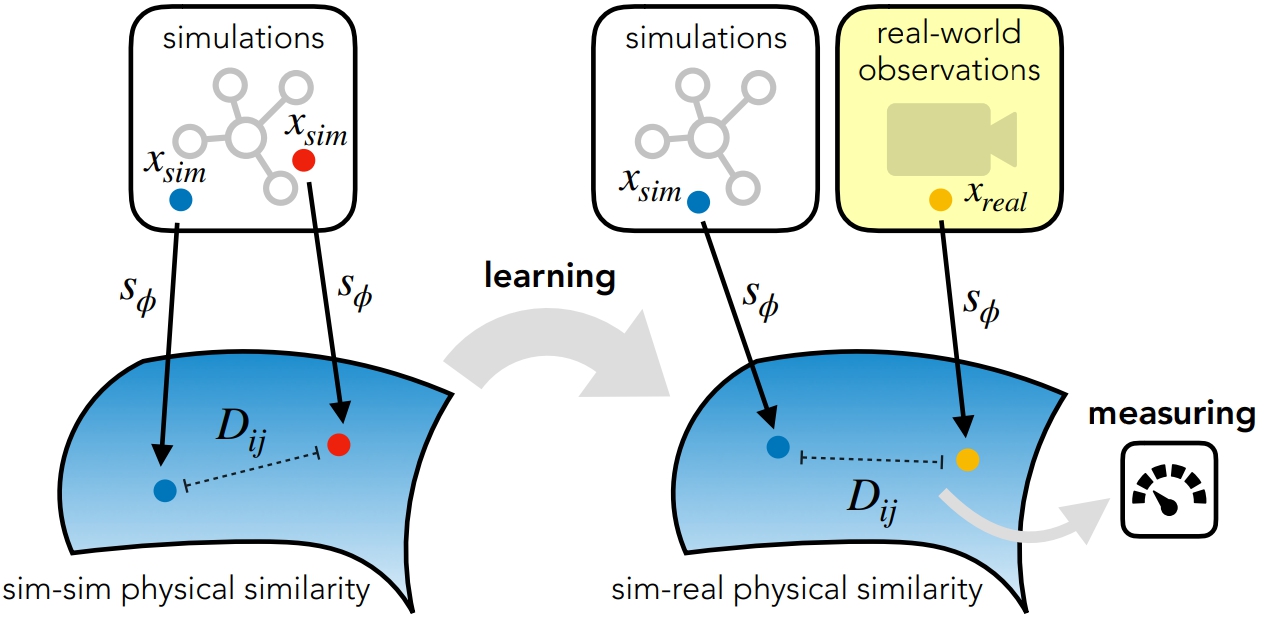
Cloth in the Wind: A Case Study of Physical Measurement through Simulation
For many of the physical phenomena around us, we have developed sophisticated models explaining their behavior. Nevertheless, measuring physical properties from visual observations is challenging due to the high number of causally underlying physical parameters – including material properties and external forces. In this paper, we propose to measure latent physical properties for cloth in the wind without ever having seen a real example before. Our solution is an iterative refinement procedure with simulation at its core. The algorithm gradually updates the physical model parameters by running a simulation of the observed phenomenon and comparing the current simulation to a real-world observation. The correspondence is measured using an embedding function that maps physically similar examples to nearby points. We consider a case study of cloth in the wind, with curling flags as our leading example – a seemingly simple phenomena but physically highly involved. Based on the physics of cloth and its visual manifestation, we propose an instantiation of the embedding function. For this mapping, modeled as a deep network, we introduce a spectral layer that decomposes a video volume into its temporal spectral power and corresponding frequencies. Our experiments demonstrate that the proposed method compares favorably to prior work on the task of measuring cloth material properties and external wind force from a real-world video.
arXiv,
2020

Actor and Action Video Segmentation from a Sentence
This paper strives for pixel-level segmentation of actors and their actions in video content. Different from existing works, which all learn to segment from a fixed vocabulary of actor and action pairs, we infer the segmentation from a natural language input sentence. This allows to distinguish between fine-grained actors in the same super-category, identify actor and action instances, and segment pairs that are outside of the actor and action vocabulary. We propose a fully-convolutional model for pixel-level actor and action segmentation using an encoder-decoder architecture optimized for video. To show the potential of actor and action video segmentation from a sentence, we extend two popular actor and action datasets with more than 7,500 natural language descriptions. Experiments demonstrate the quality of the sentence-guided segmentations, the generalization ability of our model, and its advantage for traditional actor and action segmentation compared to the state-of-the-art.
CVPR,
2018
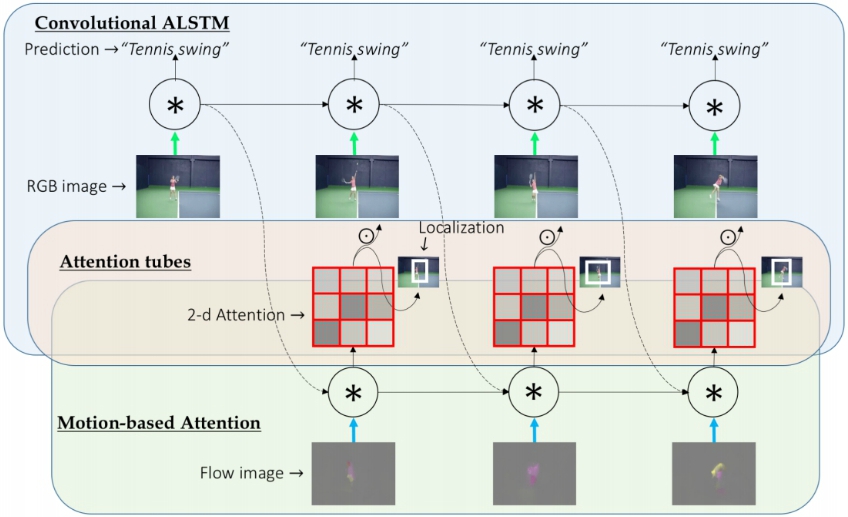
VideoLSTM convolves, attends and flows for action recognition
We present VideoLSTM for end-to-end sequence learning of actions in video. Rather than adapting the video to the peculiarities of established recurrent or convolutional architectures, we adapt the architecture to fit the requirements of the video medium. Starting from the soft-Attention LSTM, VideoLSTM makes three novel contributions. First, video has a spatial layout. To exploit the spatial correlation we hardwire convolutions in the soft-Attention LSTM architecture. Second, motion not only informs us about the action content, but also guides better the attention towards the relevant spatio-temporal locations. We introduce motion-based attention. And finally, we demonstrate how the attention from VideoLSTM can be exploited for action localization by relying on the action class label and temporal attention smoothing. Experiments on UCF101, HMDB51 and THUMOS13 reveal the benefit of the video-specific adaptations of VideoLSTM in isolation as well as when integrated in a combined architecture. It compares favorably against other LSTM architectures for action classification and especially action localization.
CVIU,
2018