VideoLSTM convolves, attends and flows for action recognition
Abstract
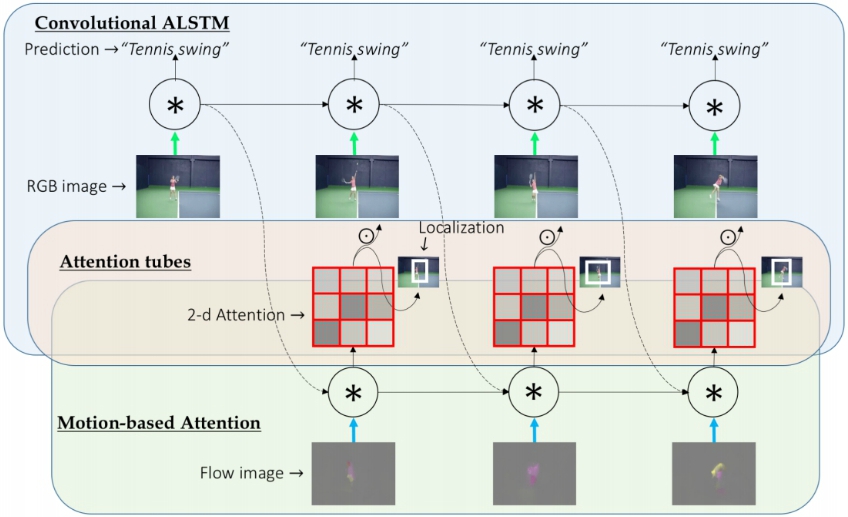
We present VideoLSTM for end-to-end sequence learning of actions in video. Rather than adapting the video to the peculiarities of established recurrent or convolutional architectures, we adapt the architecture to fit the requirements of the video medium. Starting from the soft-Attention LSTM, VideoLSTM makes three novel contributions. First, video has a spatial layout. To exploit the spatial correlation we hardwire convolutions in the soft-Attention LSTM architecture. Second, motion not only informs us about the action content, but also guides better the attention towards the relevant spatio-temporal locations. We introduce motion-based attention. And finally, we demonstrate how the attention from VideoLSTM can be exploited for action localization by relying on the action class label and temporal attention smoothing. Experiments on UCF101, HMDB51 and THUMOS13 reveal the benefit of the video-specific adaptations of VideoLSTM in isolation as well as when integrated in a combined architecture. It compares favorably against other LSTM architectures for action classification and especially action localization.